Go语言的垃圾回收:第一部分 语义
[原文] Garbage Collection In Go : Part I - Semantics
锲子
这是由三部分构成的系列中的第一篇,它将提供Go语言垃圾回收背后的语义和机制的理解。这篇文章重点介绍有关收集者语义的基础材料。
三部分系列文章的索引:
- Garbage Collection In Go : Part I - Semantics
- Garbage Collection In Go : Part II - GC Traces
- Garbage Collection In Go : Part III - GC Pacing
介绍
垃圾收集器负责跟踪堆内存分配,释放不再需要的分配,并保留仍在使用的分配。 语言是如何决定实现这种行为的方式很复杂,但是应用程序开发人员并不需要为了构建软件而了解其细节。 另外,随着语言VM或运行时版本的不同,这些系统的实现总是在变化和发展中。 对于应用程序开发人员而言,重要的是保持一个良好的工作模型,以了解其语言的垃圾收集器的行为方式,以及他们如何支持该行为而无需担心实现方式。
对于 1.12版本,Go程序语言使用一个非世代的并发三色标记和清除收集器。如果你希望可视化看到标记清除收集器如何工作,Ken Fox 写了一个很棒的文章并提供了动画。Go收集器的实现在每个Go版本中都进行了改变和发展。所以每个文章讨论的关于实现细节,当下一个语言版本发布,将不再精确。
综上所述,我将在这该文章中阐述的模型,不再聚焦于实际的实现细节。模型将聚焦于你将体验以及未来几年您应该期待看到的行为。在这篇文章中,我将与您分享收集器的行为,并说明如何支持该行为,而不管当前的实现方式或将来的实现方式如何变化。这将使您成为更好的Go开发人员。
注意:你也可以在这儿阅读更多关于垃圾回收和Go实际的收集器信息
堆并不是容器
我从来不会将堆视为可以存储和释放值的容器。重要的是要了解,没有定义“堆”的线性存储空间。 想象一下,保留给进程空间中的应用程序使用的任何内存都可用于堆内存分配。 虚拟存储或物理存储任何给定堆内存分配的位置与我们的模型无关。 这种了解将帮助您更好地了解垃圾收集器的工作方式。
收集器行为
当搜集开始,收集器通过三阶段工作来运行。其中有两个阶段会产生世界停止(STW)延迟,而另一个阶段创建的延迟会减缓应用程序的吞吐量。这三个阶段为:
- 标记设置 - STW
- 标记 - 并发
- 标记终止 -STW
这是每个阶段的细分。
标记设置 - STW
当搜集开始时,必须执行的第一个活动是打开写屏障。写屏障的目的是允许搜集器在搜集阶段维护堆上数据的完整性。因为搜集器和应用程序协程将会并发地运行。
为了打开写屏障,每个应用程序协程的运行必须被停止。这个活动通常非常迅速,平均在10到30微秒内。这就是,只要应用程序协程行为的正确即可。
注意:为了更好地理解这些调度器图表,确保已经阅读了 Go调度器 系列文章。
Figure 1
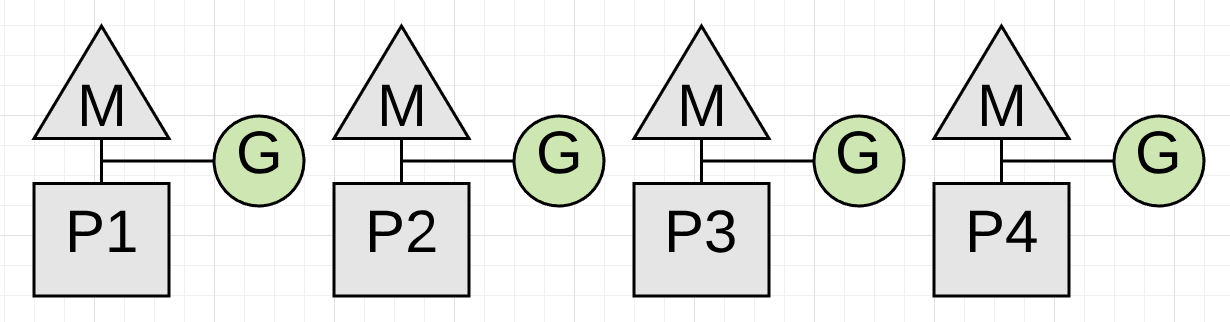
图表1展示了在垃圾收集前的4个应用程序协程的运行。4个协程中的每个必须停止。垃圾收集器这样做的唯一方式是观察并等待每个协程做出函数调用。函数调用确保协程以一种安全点的方式被停止。当其他做出了函数调用而其中一个没有会发生什么?
Figure 2
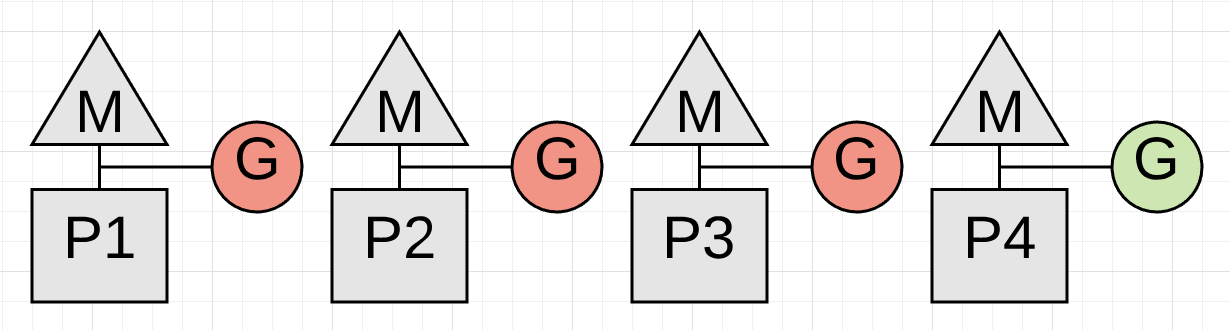
图表2展示了一个真正的问题。收集不能开始,直到运行在 P4 上的协程被停止,这不可能发生,因为它处于执行某些数学运算的紧密循环(tight loop)中。
Listing 1
|
|
清单1展示了运行于P4上的协程正在执行代码。取决于切片的大小,协程可能运行一个不确定的时间,而没有机会被停止。这类代码可能会使收集开始时停滞不前。 更糟糕的是,其他P在收集器等待时无法为其他goroutine提供服务。 至关重要的一点是,goroutine在合理的时间范围内进行函数调用。
注意:这在1.14版本中,语言团队通过在调度器中增加一个抢占技术修改了该问题
标记 - 并发
一量写屏障被打开,收集器开始进入标记阶段。收集器要做的第一件事是其自身使用可用CPU容量的25%。搜集器使用协程做搜集工作,需要和应用程序协程使用相同的 P 和 M 。这意味着对于我们的4线程Go程序,一个完整的P将专用于收集工作。
Figure 3
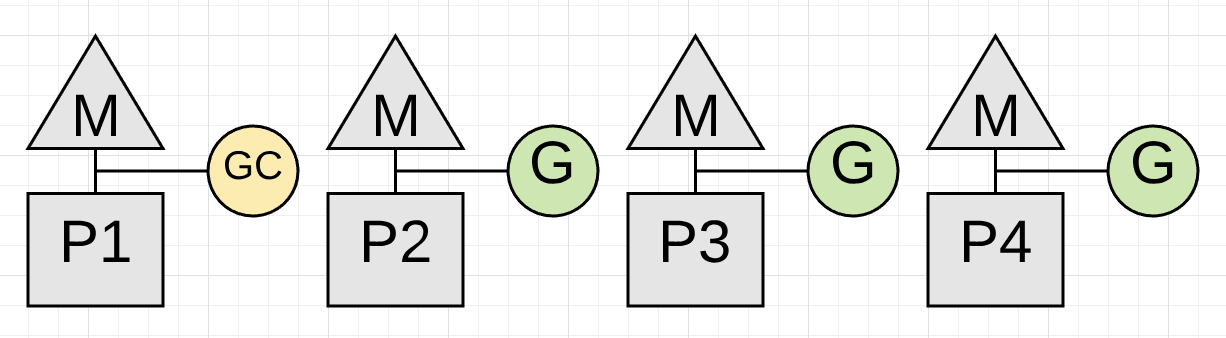
图表3展示了在搜集期间,搜集器本身是如何使用 P1 的。现在搜集器可以开始标识阶段。标记阶段包括标记堆内存中仍然使用的值。这项工作首先检查所有现有的协程的栈,以找到指向堆内存的根指针。然后,收集器必须从那些根指针遍历堆内存图。在 P1 上进行标记工作时,可以同时在 P2,P3 和 P4 上继续进行应用程序工作。这意味着搜集器的影响已经最小化到当前 CPU 容量的 25%。
我希望这是故事的结束,但并不是。如果在收集期间发现,专用于 P1 上的 GC 协程无法在使用中堆内存达到其极限之前完成标记工作,该怎么办?如果这3个协程只有一个执行应用程序工作,那搜集器将无法及时完成怎么办?在这种情况下,必须放慢新的分配速度,特别是从该协程中放慢速度。
如果搜集器决定它需要减少分配速度,它将募集应用协程来协助其标记工作。这被称为标记辅助。任何应用程序协程将被放置在标记辅助中的时间与它添加到堆内存中的数据量成正比。 标记辅助的一个积极的副作用是,它有助于更快地完成搜集。
Figure 4
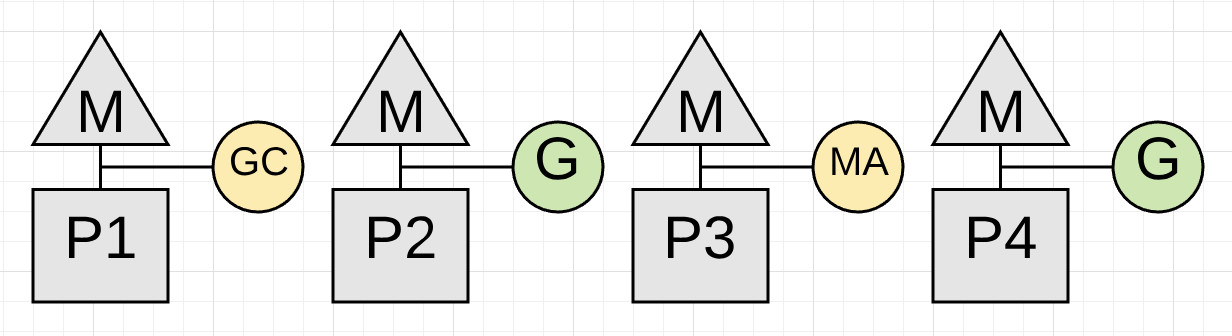
图表4展示了现在运行于 P3 上的应用协程是如何进行标记辅助并帮助搜集工作的。希望其他应用程序协程也要也参与到其中。分配繁重的应用程序可能会看到大多数正在运行的Goroutine在收集过程中执行少量的Mark Assist。
收集器的一个目标是消除对Mark Assists的需求。 如果任何给定的收集最终需要大量的Mark Assist,则收集器可以更早地开始下一个垃圾收集。 这样做是为了减少下一次收集所需的“标记辅助”量。
标记终止 - STW
当收集工作完成,下一个阶段是标记终止。这是写屏障被关闭的时候,执行各种清理任务,然后计算下一个收集目标。 在标记阶段发现自己处于紧密循环中的Goroutine也可能导致标记终止STW延迟被延长。
Figure 5
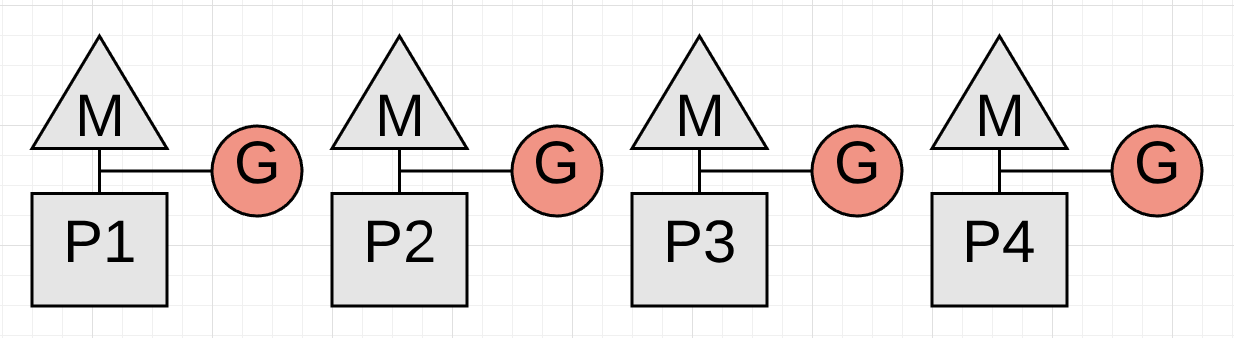
图表5展示了当标记终止阶段完成,所有的协程是如何停止的。这个活动通常平均在 60 到 90 微秒内。该阶段的完成不需要世界停止,但是通过使用世界停止,代码将更简单,而且增加的复杂性也不值一提。
当收集完成,每个 P 可以再次被应用协程使用,同时应用程序将恢复正常工作。
Figure 6
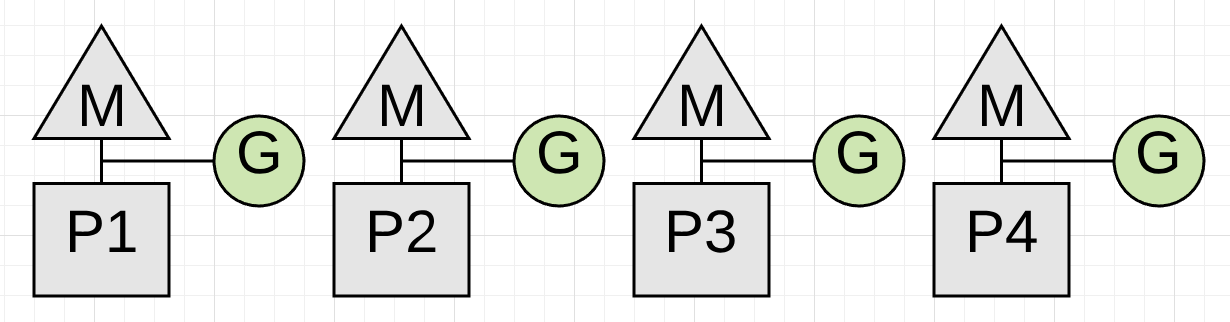
图表6显示了当收集工作完成后,所有可用的 P 现在是如何再次处理应用程序工作的。应用程序恢复到收集开始前的工作状态。
清除 - 并发
在收集完成后,另一个发生的活动被称为清除。清除是指回收与堆内存中未标记为使用中的值相关联的内存。这个活动发生在当应用程序协程试图在堆内存中分配新值时。清除的延迟增加了在堆内存中执行分配的开销,并且与垃圾回收相关的任何延迟无关。
下面是在我的拥有12个物理线程可用于执行协程的机器上的追踪示例
Figure 7
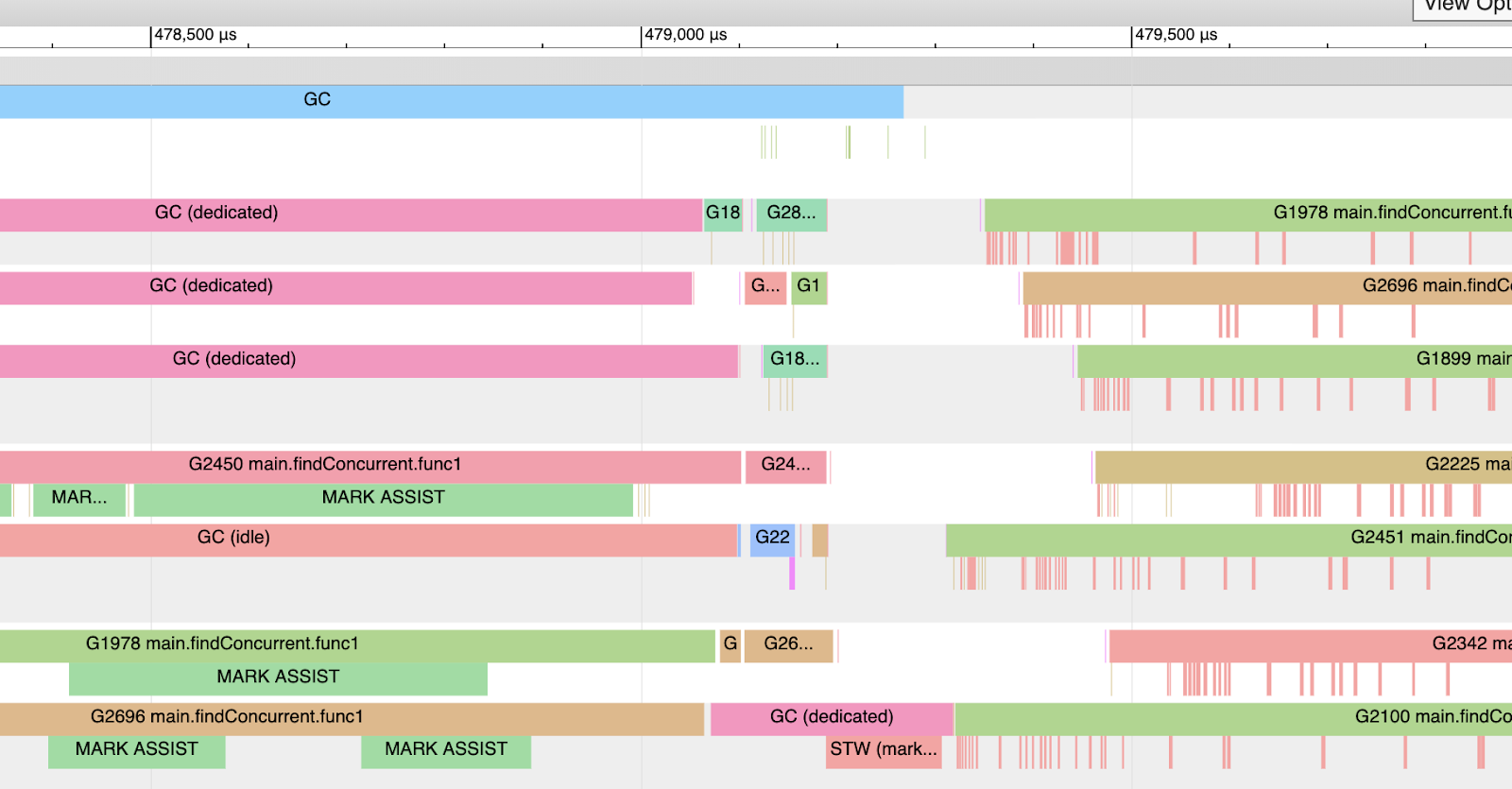
图表7展示了追踪的部分快照。你可以看到在这个收集(图表顶部的蓝色GC行)协程中,12个P中的三个是如何专门用于GC的。你可以看到在这期间协程 2450, 1978 和 2696 正在进行大量的标记辅助工作,而没不是它的应用工作。在收集的最后,仅有一个 P 专门用于GC,执行最后STW(标记终止)工作。
在收集完成后,应用程序将恢复全速运行。除了这些协程下方看到的许多玫瑰色的线条。
Figure 8
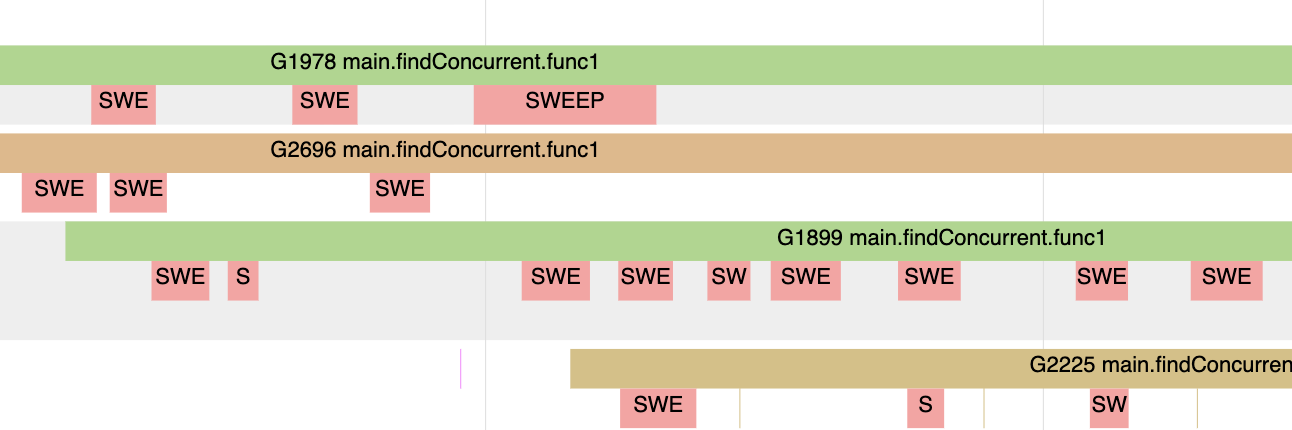
在图表8中展示了这些标记为玫瑰色的行代表的是当协程进行清除工作,而不是它们的应用程序工作的时刻。这些是协程尝试在堆上分配新的值的时刻。
Figure 9
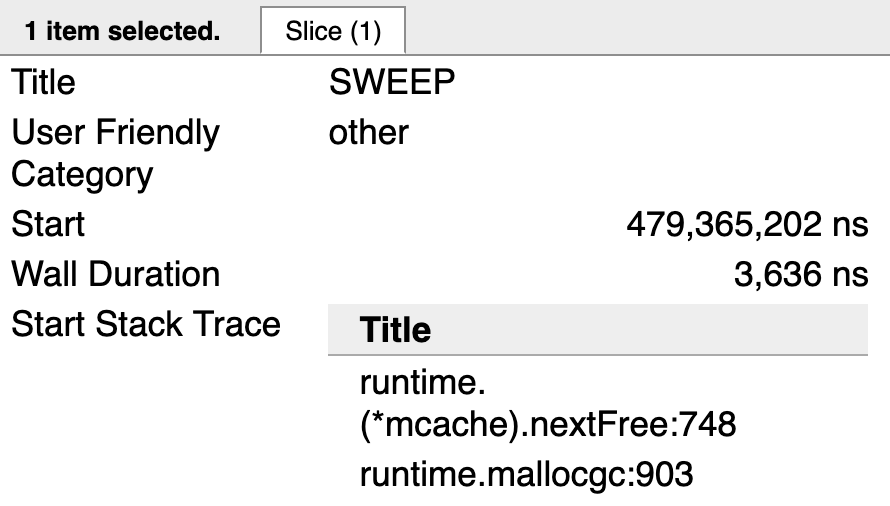
图表9展示了一个处于标记活动的协程的堆跟踪结果。调用 runtime.mallocgc 是在堆内存上分配 一个新值的调用。对 runtime.(*mcache).nextFree 的调用导致了清除活动。当在堆内存上不再有回收的分配,将不会看到对 nextFree 的调用。
刚才描述的收集行为,仅在当收集已经开始并运行时发生。在决定收集何时开始时,GC百分比配置选项扮演重要角色。
GC百分比
在运行时有一个配置选项被称为GC百分比,它默认被设置为100。此值表示在下一个收集必须开始之前可以分配多少新堆内存的比率。 将GC百分比设置为100表示,根据收集完成后标记为活动的堆内存量,下一个收集必须在100%的新分配添加到堆内存之前或之前开始。
作为示例,想象收集后,堆内存上仍有2MB在使用中。
注意:在这篇文章中的图表不代表使用Go时真正的 profile。Go中的堆内存通常是分散且凌乱的,而且图像所代表的分离度也不高。这些图提供了一种更容易理解的方式可视化内存,该方式对于您将遇到的行为是准确的。
Figure 10

图表10展示了在最近收集完成后,堆内存中有2MB在使用中。由于GC百分比为100%,下一个收集需要在堆内存中再添加2MB或之前开始。
Figure 11

图表11展示了堆内存中现在有另外2MB在使用中。这将触发一个收集。观察所有这些活动的方式,是为发生的每一个收集生成一个GC追踪。
GC追踪
GC追踪在运行任何应用程序时,使用带有 gctrace= 选项的环境变量 GODEBUG 时生成。每当GC发生时,运行时将在 stderr 上写一个GC追踪信息。
Listing 2
|
|
清单2显示了如何使用 GODEBUG 变量生成GC追踪。清单同时显示了在运行Go应用程序时,生成了3个追踪。
通过查看清单中的第一条GC跟踪行,可以深入了解GC跟踪中每个值的含义。
Listing 3
|
|
清单3显示了第一条GC跟踪行中的实际数字,按值的含义细分了这些数字。 我最终将讨论其中的大多数值,但现在仅关注跟踪1405的GC跟踪的内存部分。
Figure 12
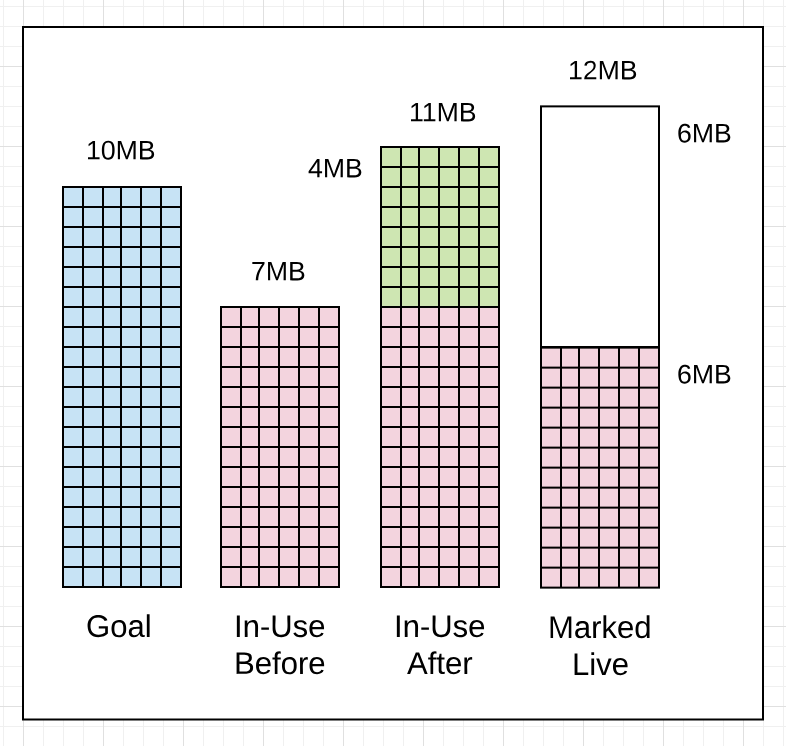
Listing 4
|
|
在清单4中GC追踪行告诉我们的是,在标记工作开始之前,堆内存中在使用的数量是 7MB。当标记工作完成后堆内存中在使用的数量将达到 11MB。这意味着在收集期间,发生了额外的 4MB 的分配。当标记工作完成后,堆内存中被标记为活动的数量为 6MB。这意味着,在下一次收集需要开始前,应用可以增加堆内存在使用中的数量为 12MB(活动堆大小的100%是6MB)。
你可以看到收集器的目录丢失了 1MB。在标记工作完成之后,堆内存中使用中的数量是 11MB 而不是 10 MB。这是可以的,因为目标是基于当前堆内存中在使用的数量来计算的,标记为活动的堆内存量以及有关收集运行时将发生的其他分配的计时计算得出的。 在这种情况下,应用程序执行的操作需要在标记后使用比预期更多的堆内存。
如果你看下下一次GC追踪行(1406),你将会在2ms内事情是如何改变的。
Figure 13
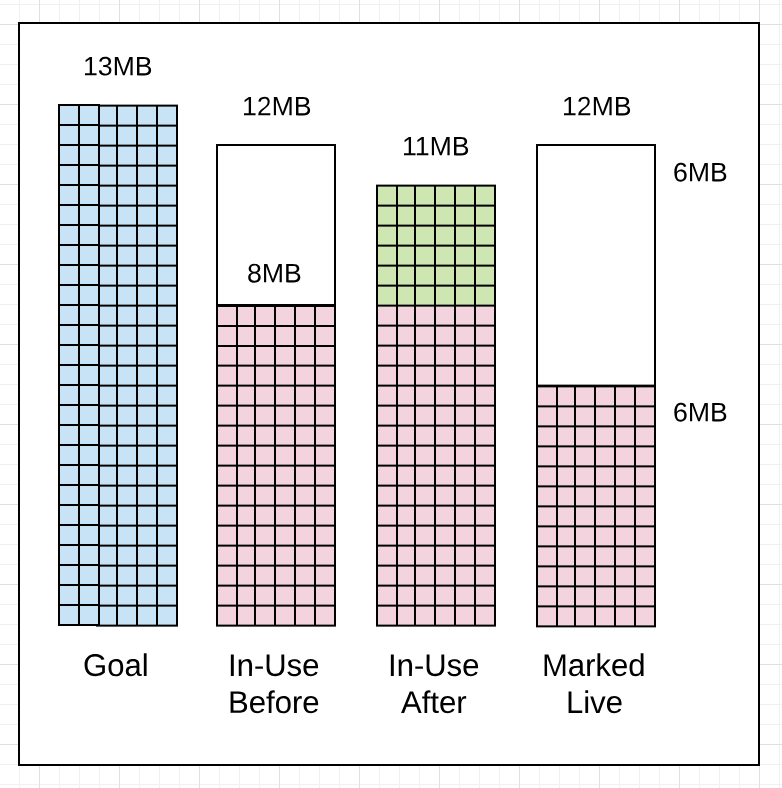
Listing 5
|
|
清单5展示了收集如何在上一个收集开始后的2ms(6.068s和6.070s)之间启动,即使正在使用的堆内存仅达到允许的12MB中的8MB。 请务必注意,如果收集器认为最好尽早开始收集。 在这种情况下,它可能启动得较早,因为应用程序分配过多,并且收集器希望减少此收集期间的“标记辅助”延迟时间。
还有两点需要注意。 这次收集者保持在其目标之内。 标记完成后正在使用的堆内存量为11MB而不是13MB,减少了2MB。 标记完成后标记为活动的堆内存量相同,为6MB。
作为旁注。 您可以通过添加 gcpacertrace = 1标志从GC跟踪中获取更多详细信息。 这使收集器打印有关并发起搏器内部状态的信息。
Listing 6
|
|
运行 GC 追踪可以告诉我们很多关于程序健康和收集器节奏的信息。收集器运行的节奏在收集处理中扮演发重要的角色。
节奏(Pacing)
收集器有个节奏算法用来决定收集何时开始。算法依赖一个回馈循环,收集器使用该循环来收集有关运行的应用程序以及应用程序施加在堆上的压力的信息。压力可以定义为给定的时间内,应用程序在堆内存上分配的速度。正是该压力决定了收集器需要运行的节奏。
在收集器开始收集之前,它计算自己相信的完成收集所需要的时间。然后,一旦收集开始运行,延迟将会施加到运行的应用上,它会减缓应用程序的工作。每次收集都会增加应用程序的整体延迟。
一个误解是认为放慢收集器的速度是提高性能的一种方法。 这个想法是,如果您可以延迟下一个收集的开始,那么就延迟了它将带来的延迟。 同情收集器并不是要放慢节奏。
你可以决定修改GC百分比值为大于100的数。这将在下次收集开始时可以分配到堆内存上的量。这将导致收集速度的减缓。不要想着这样做。
Figure 14

图表14显示了更改GC百分比将如何更改允许下一个收集开始之前分配的堆内存量。 您可以直观地观察收集器在等待更多堆内存投入使用时如何放慢速度。
试图直接影响收集的速度与同情收集器无关。 这实际上是要在每个收集之间或收集期间完成更多工作。 通过减少任何工作添加到堆内存中的分配数量或数量,可以影响到这一点。
注意:这个想法也是用最小的堆来实现所需的吞吐量。 请记住,在云环境中运行时,尽量减少对堆内存等资源的使用非常重要。
Figure 15
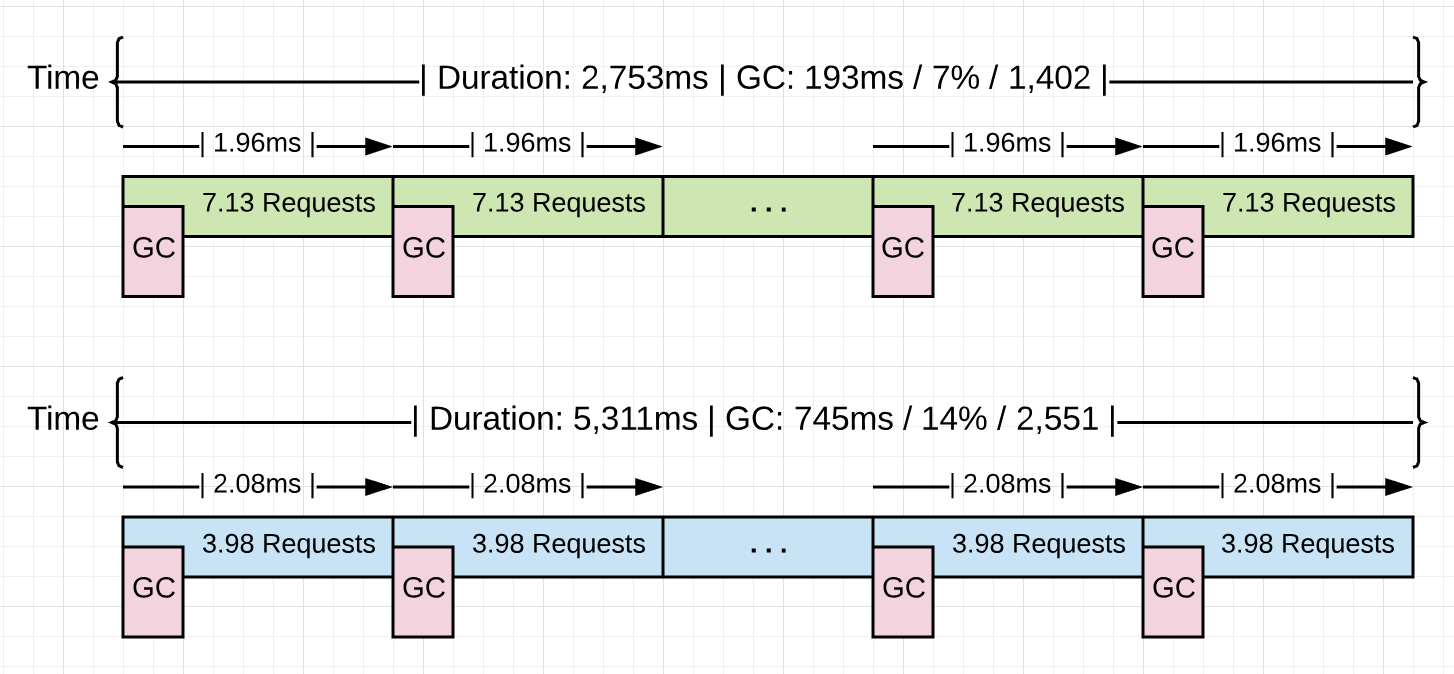
清单15显示了正在运行的Go应用程序的一些统计信息,该统计信息将在本系列的下一部分中使用。当通过应用程序处理10k请求时,蓝色版本显示不是没有进行任何优化时,应用程序的统计信息。绿色版本显示的是,对于相同的10k请求,在发现4.48GB非生产性内存分配并将其从应用程序中删除后的统计信息。
查看两个版本的平均收集速度(2.08毫秒对1.96毫秒)。它们实际上是相同的,大约为2.0ms。这两个版本之间的根本变化是每个集合之间要完成的工作量。该应用程序从每个收集处理3.98到7.13请求。以相同的速度完成的工作量增加了79.1%。如您所见,收集并没有随着分配减少而放慢速度,而是保持不变。胜利来自在每收集之间完成更多的工作。
调整收集速度以延迟延迟成本不是提高应用程序性能的方式。这是关于减少收集器需要运行的时间,而这又将减少造成的延迟成本。已经解释了收集器造成的等待时间开销,但是为了清楚起见,让我再次对其进行总结。
收集延迟开销
在运行应用程序时,每个收集会造成两种类型的延迟。第一个是窃取CPU容量。窃取CPU容量的副作用意味着你的应用程序在收集期间并未全速运行。应用程序协程现在正和收集器协程共享 P 或协助收集(标记辅助 Mark Assist)。
Figure 16
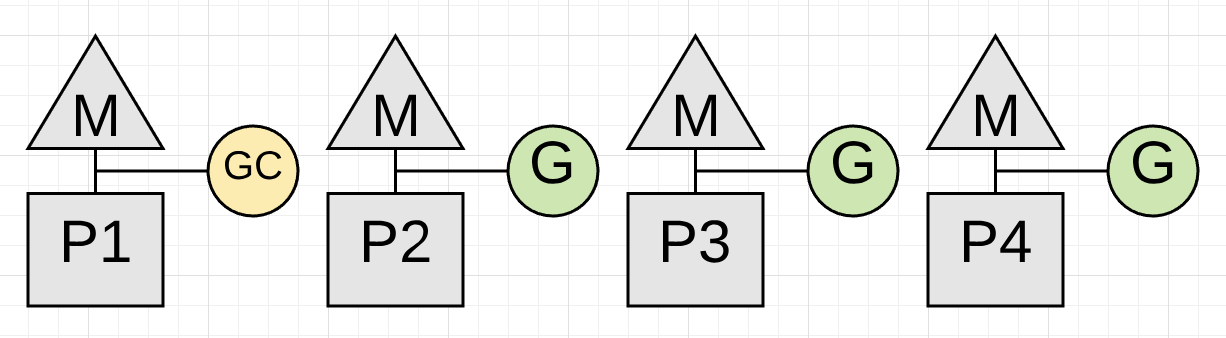
图表16 显示了应用程序如何仅使用其CPU容量的75%进行应用程序工作。 这是因为收集器本身具有专用的P1。 这将是大多数收集器。
Figure 17
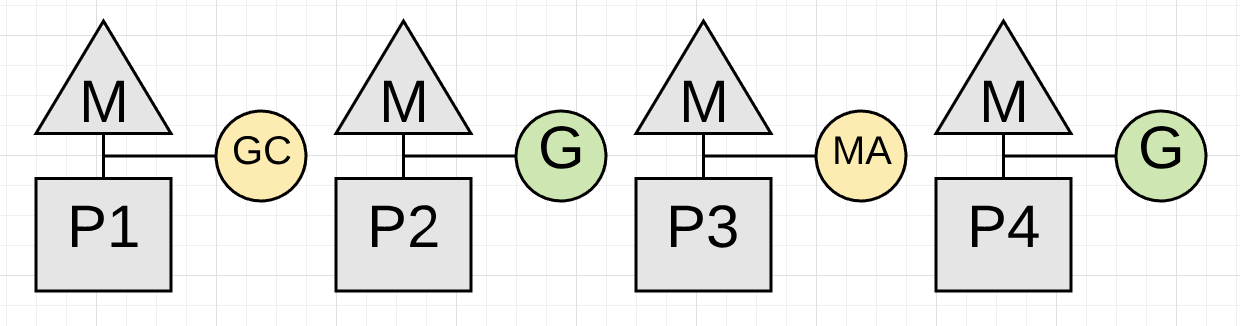
图表17显示了应用程序此时(通常只有几微秒)如何在使用CPU容量的一半进行应用程序工作。这是因为P3上的协程正在执行 ”标记辅助“,并且收集器具有专用的P1。
注意:标记通常每MB的活动堆占用4 CPU毫秒的时间(例如,估算标记阶段将运行多少毫秒,以MB为单位的活动堆大小除以0.25 * CPU数量)。 标记实际上以大约1 MB / ms的速度运行,但只有四分之一的CPU。
造成的第二个延迟是收集期间发生的STW延迟量。 STW时间是没有应用程序Goroutines执行其任何应用程序工作的时间。 该应用程序实际上已停止。
Figure 18
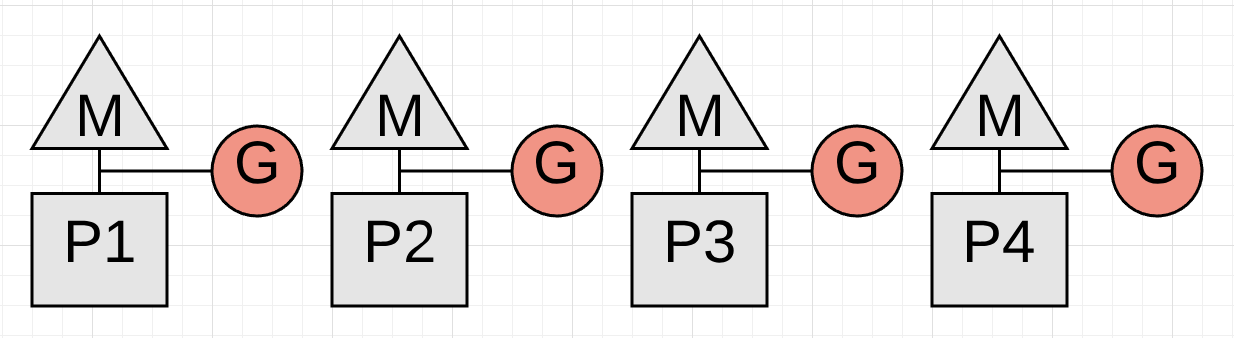
图表18显示了所有脚边程停止时的STW延迟。这在每次收集时发生两次。如果你的应用程序是健康的,收集器能够在大多数的收集期间保持总共的STW时间小于100微秒。
你现在知道收集器的不同阶段,内存大小如何,步调如何工作以及收集器对正在运行的应用程序造成不同的延迟。有了这些知识,你就可以回答关于如何支持收集器的问题了。
同情(Being Sympathetic)
同情收集器是关于如何减少堆内存压力。记住,压力可以被定义为在给定的时间内,应用程序分配堆内存的速度有多快。当压力减少,施加到收集器的延迟也相应的减少。正是GC的延迟减缓了你的应用程序。
减少GC延迟的方式是通过从你的应用程序中辨别并移除不必要的分配。可以通过多种方式帮助您做这些。
- 维护尽可能小的堆
- 找到优化一致的速度
- 每次收集都保持在目标之内
- 最小他每次收集,STW和标记辅助的持续时间
所有这些都有助于减少收集器对正在运行的应用程序造成的延迟量。这将提高应用程序的性能和吞吐量。收集的速度与它无关。您还可以做其他事情,以帮助您做出更好的工程决策,从而减轻堆的压力。
了解你的应用程序正在执行的工作负载的性质
了解你的工作负载意味着确保你使用了合适数量的协程来完成您的工作。CPU vs IO 密集型工作是不同的,并且工程决策也需要不同。
https://www.ardanlabs.com/blog/2018/12/scheduling-in-go-part3.html
了解数据的定义以及它是如何传递给应用程序的
了解你的数据意味着知道你正试图解决的问题。数据语义的一致性是维护数据完整性的关键部分,它使您可以(通过阅读代码)知道在栈上选择堆分配时的情况。
https://www.ardanlabs.com/blog/2017/06/design-philosophy-on-data-and-semantics.html
结论
如果您花时间专注于减少分配,那么您将作为Go开发人员尽一切努力来同情垃圾回收器。 您不会编写零分配的应用程序,因此重要的是要认识到生产性分配(对应用程序有帮助的分配)和非生产性分配(对应用程序有害的分配)之间的区别。 然后,您对垃圾收集器充满信心和信任,以使堆保持健康,并使您的应用程序始终运行。
拥有一个垃圾收集器是一个不错的权衡。 我将承担垃圾收集的开销,这样我就不会内存管理的负担。 Go是关于让您作为开发人员提高工作效率,同时仍然编写足够快的应用程序。 垃圾收集器是实现这一目标的重要组成部分。 在下一篇文章中,我将向您展示一个示例Web应用程序,以及如何使用该工具查看所有这些操作。