Go语言的垃圾回收 第三部分 GC速度
[原文] Garbage Collection In Go : Part III - GC Pacing
锲子
这是由三部分构成的系列中的第二篇,它将提供Go语言垃圾回收背后的语义和机制的理解。这篇文章重点介绍GC如何自我调整。
三部分系列文章的索引:
- Garbage Collection In Go : Part I - Semantics
- Garbage Collection In Go : Part II - GC Traces
- Garbage Collection In Go : Part III - GC Pacing
介绍
在第二篇文章,我向您展示了垃圾收集器的行为,以及如何使用工具查看收集器注入到你运行的应用系统的延迟。我带领您运行一个真正的web应用程序并向您展示了如何生成GC追踪文件和应用配置文件。然后我向您展示了如何分析这些工具的输出,所以你可以找到提升您应用程序性能的方法。
文章最后的结论和第一篇的一样:如果你减少堆压力,您将减少延迟开销,进而提升应用程序的性能。同情垃圾收集器的最佳策略是每个工作运行时减少分配的数目和数量。在这篇文章中,我将展示 pacing 算法如何能够随着时间的推移确定给定工作负载的最佳速度。
并发示例代码
我将使用位于这个链接的代码
https://github.com/ardanlabs/gotraining/tree/master/topics/go/profiling/trace
该程序确定在RSS新闻提要文档的集合中可以找到特定主题的频率。 跟踪程序包含不同版本的查找算法,以测试不同的并发模式。 我将专注于freq,freqConcurrent和freqNumCPU版本的算法。
注意:我在拥有12个硬件线程的Intel i9处理器的 Macbook Pro 机器上使用go1.12.7运行代码。在不同的架构,操作系统和Go版本上会看到不同的结果。这篇文章的核心应该是一样的。
我首先使用 freq 版本作为开始。它代表的是一个非并发顺序版本的程序。这将为随后的并发版本提供一个基线。
Listing 1
|
|
清单1显示了 freq 函数。此顺序版本涵盖了文件名的集合,并执行四个操作:打开,读取,解码和搜索。 它对每个文件一次执行一次这样的操作。
当在自己机器上使用这个版本的 freq ,获得的输出如下:
Listing 2
|
|
通过 time 的输出,可以看到,这个程序使用大约 2.5 秒来处理 4000 个文件。查看花费在垃圾回收上的时间百分比是 nice 的事。你可以通过看程序的追踪来做这件事。由于这是一个启动和完成的程序,因此可以使用跟踪包来生成跟踪。
Listing 3
|
|
清单3显示了你需要从程序中生成追踪的代码。在导入来自于标识库 runtime 目录的 trace 包之后,调用 trace.Start 和 trace.Stop 。将跟踪输出定向到 os.Stdout 简化了代码。
使用此代码后,现在您可以重新生成并运行该程序。不要忘记将 stdout 重定向到文件
Listing 4
$ go build
$ time ./trace > t.out
Searching 4000 files, found president 28000 times.
./trace > t.out 2.67s user 0.13s system 106% cpu 2.626 total
100多毫秒被添加到运行时,但是这是预期的。追踪捕获每次函数调用前后的微秒数重要的是,现在有一个名为 t.out 的文件,其中包含跟踪数据。
为了看追踪,追踪数据需要通过追踪工具被运行
Listing 5
$ go tool trace t.out
运行该命令,然后大下面的屏幕中打开Chrome浏览器。
注意:追踪工具使用 Chrome 浏览器的内置的工具。此工具仅适用于 Chrome 浏览器。
Figure 1
图1显示了当追踪工具启动时,呈现的9个链接。现在重要的链接是第一个,它叫 View trace 。当你选择了这个链接,你会看到类似下面的内容。
Figure 2
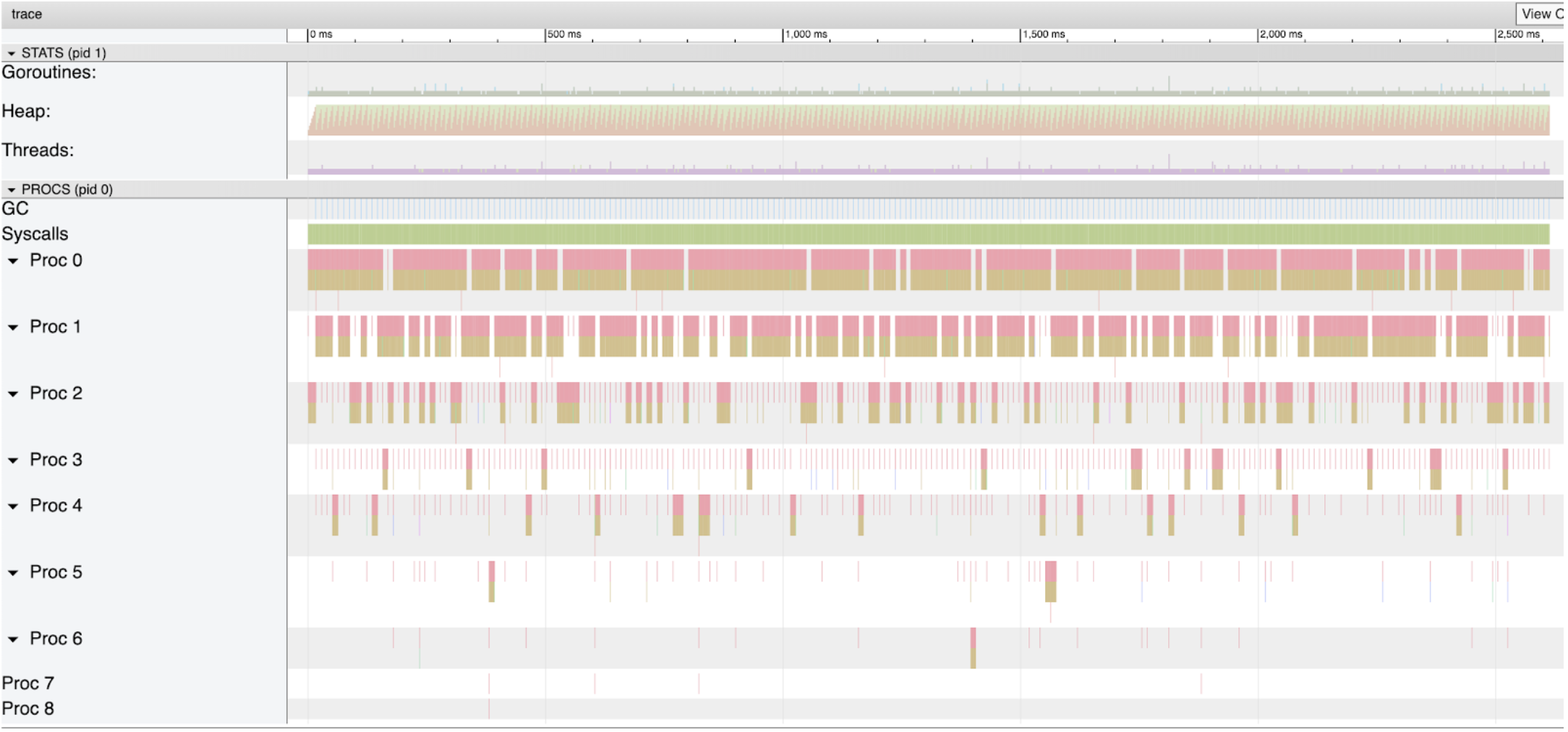
图2显示了从程序运行在我的机器上的整个追踪窗口。对于本文,我将聚焦与垃圾回收有关的部分。这是标签为 Heap 的第二部分和标签为 GC 的第四部分。
Figure 3
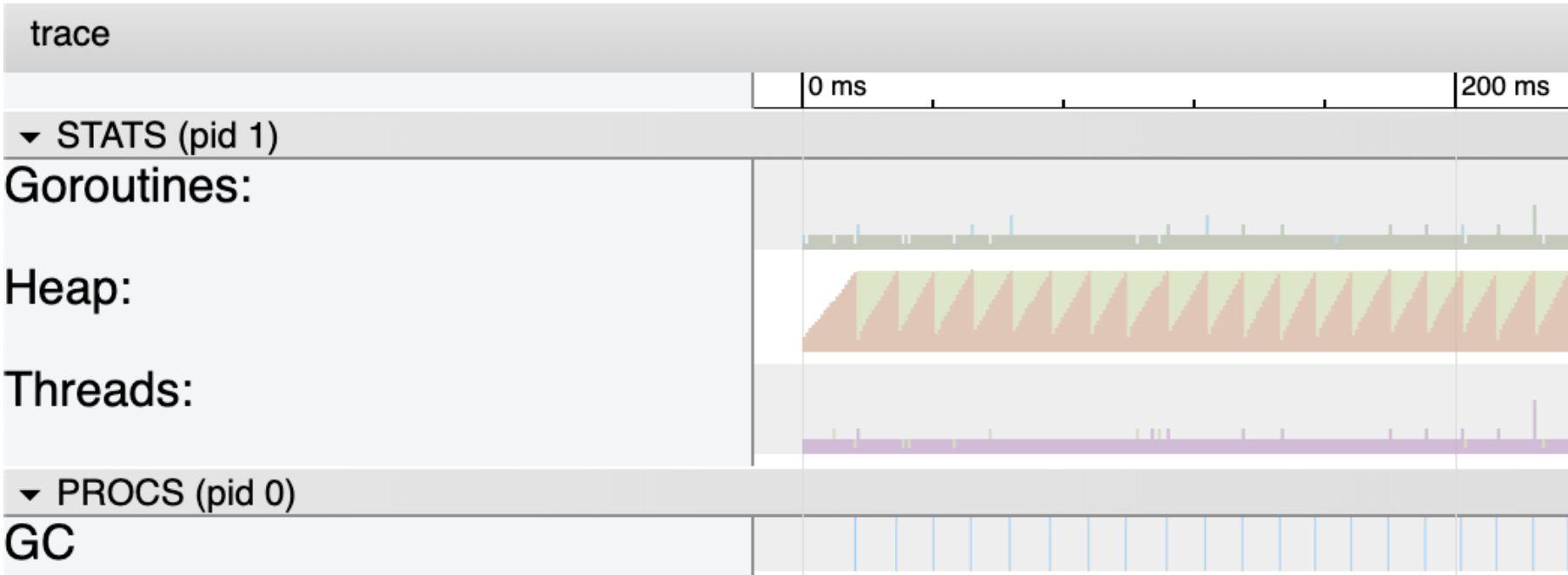
图3详细显示了跟踪的前200毫秒。 将注意力集中在Heap(绿色和橙色区域)和 GC(底部的蓝线)上。 Heap 部分向您展示了两件事。 橙色区域是在任何给定的微秒内堆上当前的使用空间。 绿色是将触发下一个集合的堆中正在使用的空间量。 这就是为什么每次橙色区域到达绿色区域的顶部都会进行垃圾收集的原因。 蓝线代表垃圾收集。
在此版本的程序中,在整个程序运行期间,堆中正在使用的内存保持在〜4 meg。 要查看有关发生的所有单个垃圾收集的统计信息,请使用选择工具并在所有蓝线周围绘制一个框。
Figure 4

图4显示了如何使用箭头工具在蓝线周围画一个蓝框。你想在每个行上画框。框内的数字表示从图表中选择的项目所消耗的时间。 在这种情况下,选择接近316毫秒(ms,μs,ns)来生成此图像。 选中所有蓝线后,将提供以下统计信息
Figure 5

图5显示了图中的所有蓝线都在15.911毫秒标记到2.596秒标记之间。 有232个垃圾收集代表了64.524毫秒的时间,平均收集时间为287.121微秒。 知道程序运行需要2.626秒,这意味着垃圾回收仅占总运行时间的2%。 从本质上讲,垃圾收集器对于运行该程序来说是微不足道的成本。
有了基线,可以使用并发算法来执行相同的工作,从而希望加快程序运行速度。
Listing 6
|
|
清单6显示了 freq 的一个可能的并发版本。该版本的核心设计模式是使用了扇出模式。对于在 docs 集合中列出的每个文件,就创建一个协程来处理它。如果有4000个文档需要处理,则使用4000个协程。该算法的一个优势是它是利用并发的最简单的方式。每个协程仅处理一个文件。可以使用 WaitGroup 来执行等待处理每个文档的编排,并且原子指令可以使计数器保持同步。
该算法的劣势是文档数或核心数改变时扩展性不好。所有的goroutine都将有时间在程序启动时尽早运行,这意味着大量内存将被快速消耗掉。在第12行添加 found 的变量也存在缓存一致性问题。由于每个内核为此变量共享相同的缓存行,这将导致内存碰撞。当文件数或核数增加时将变得更糟。
使用该代码,现在可以重新构建并再将运行程序。
Listing 7
|
|
可以在清单7的输出中看到,程序现在使用 951ms处理同样的4000个文件。性能有大约64%的提升。看一下追踪
Figure 6
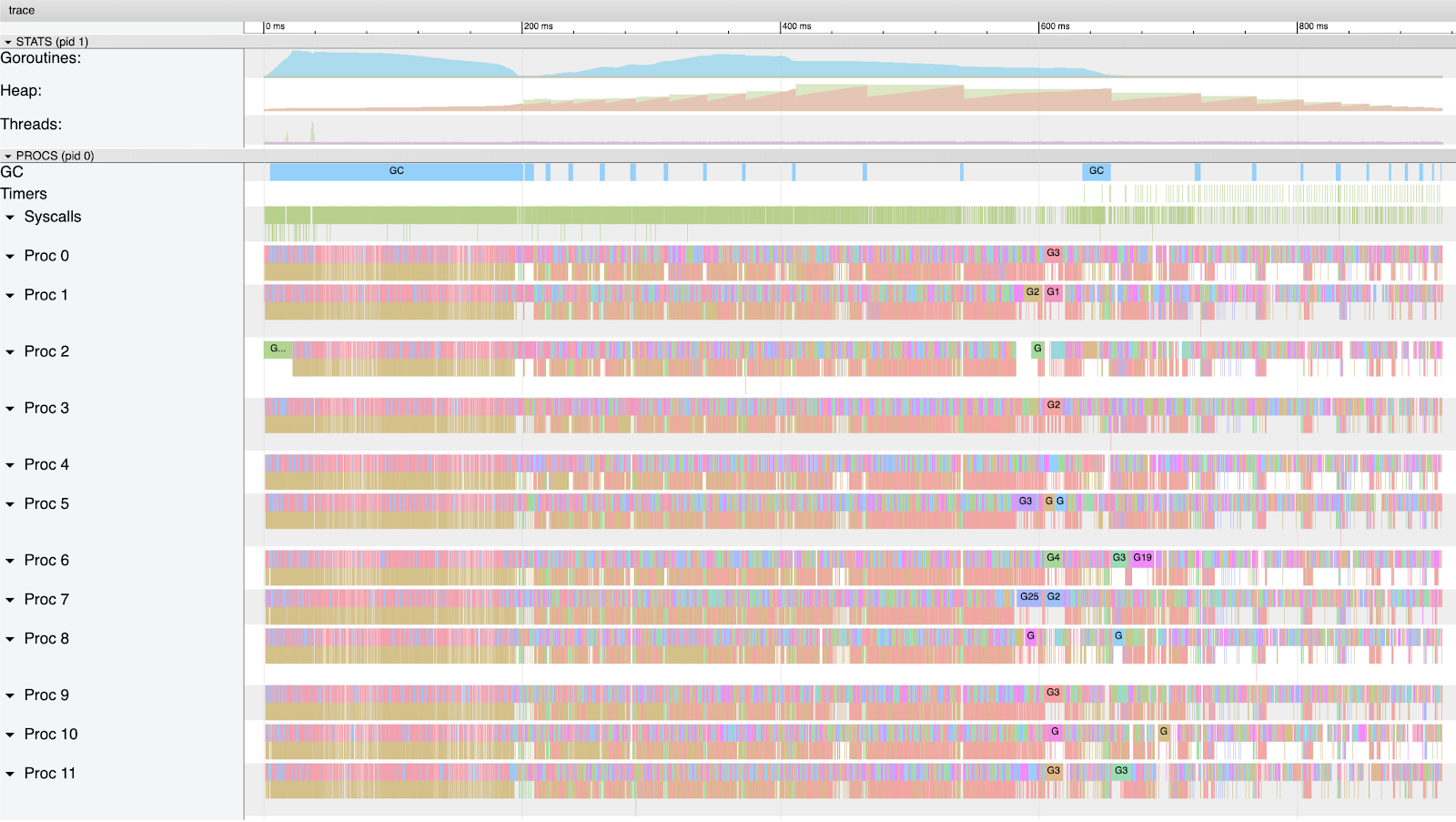
图6显示了我的机器被该版本的程序使用了多少CPU容量。图表开头的有很多的密度。这是因为所有的协程被创建,他们运行并开始尝试在堆一分配内存。一旦分配了前4兆(meg即兆的意思)的内存(很快),就会启动GC。在GC期间,每个协程都有时间运行,并且大多数协程在堆上请求内存时都处于等待状态。到该GC完成时,至少有9协程会继续运行,堆内存增加到大约26兆。
Figure 7

图7显示了很大一部分goroutine在第一个GC的大部分处于Runnable和Running状态,以及如何迅速重新启动。 请注意,堆概要文件看起来是不规则的,并且收集没有像以前那样有规律地进行。 如果仔细观察,第二个GC几乎会在第一个GC之后立即启动。
如果您选择此图中的所有收集,您将看到以下内容。
Figure 8

图8显示图中的所有蓝线都在4.828毫秒标记到906.939毫秒标记之间。 有23个垃圾收集代表了284.447毫秒的时间,平均收集时间为12.367毫秒。 知道该程序需要951毫秒才能运行,这意味着垃圾回收约占总运行时间的34%。
与顺序版本相比,这在性能和GC时间上都存在重大差异。 但是,以并行方式运行更多goroutine可以使工作完成的速度提高约64%。 成本是需要更多的机器资源。 不幸的是,在高峰时,一次在堆上使用了约200兆的内存。
有了并发基准,下一个并发算法将尝试利用资源提高效率。
Listing 8
|
|
清单8显示 freqNumCPU 版本的程序。该版本的核心设计模式是使用池化模式。基于逻辑处理器数的协程池来处理所有的文件。如果有12个可用的逻辑处理器,则会使用12个协程。该算法的优势是它使程序的资源使用从头到尾保持一致。由于使用固定数据的协程,在任何时候只需要给定这12个协程所需要的内存。这也解决了内存抖动导致的缓存一致性问题。这是因为在14行调用原子指令只发生少量的次数。
这个算法的劣势是更复杂了。它增加了通道的使用来满足池中协程的所有工作。在使用池的任何时间,为池标识“正确”数量的goroutine都是很复杂的。 通常,我给每个逻辑处理器1个goroutine来启动池。 然后执行负载测试或使用生产指标,可以计算出池的最终值。
使用此代码后,现在您可以重新生成并运行该程序。
使用该代码,现在可以重建并再次运行程序。
Listing 9
$ go build
$ time ./trace > t.out
Searching 4000 files, found president 28000 times.
./trace > t.out 6.22s user 0.64s system 909% cpu 0.754 total
可以从清单9的输出中看到,现在程序使用 754毫秒来处理同样的4000个文件。该程序快了约200毫秒,这对于这种小负载而言非常重要。看一下追踪。
Figure 9

图9显示了这个版本的程序如何使用了我机器上CPU的所有容量。如果仔细观察,该程序将再次具有一致的节奏。与顺序版本非常相似。
Figure 10
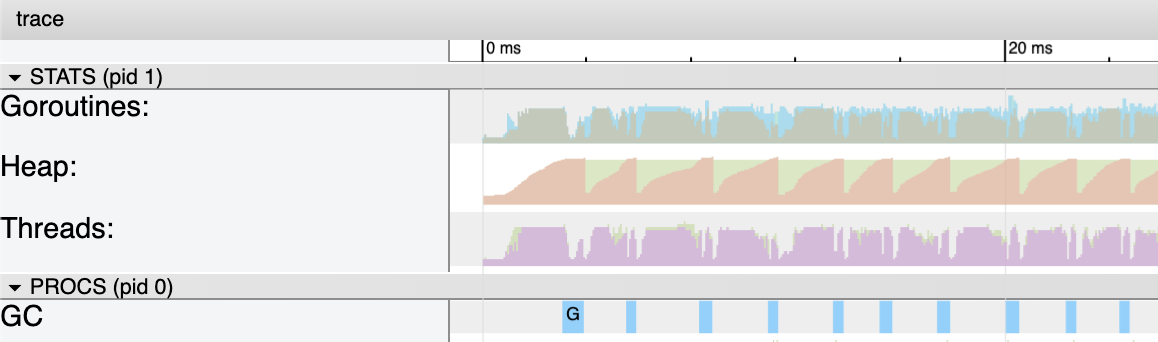
图10显示了如何在程序的前20毫秒中更仔细地查看核心指标。 收集肯定比顺序版本长,但有12个goroutine正在运行。 在程序的整个运行过程中,堆中正在使用的内存保持在〜4 meg。 同样,与程序的顺序版本相同。
如果您选择此图中的所有集合,您将看到以下内容。
Figure 11

图11显示了表中所有蓝线处于 3.055毫秒标记到719.928毫秒标记之间。有代表177.709毫秒时间的467个垃圾回收和平均占用380.535毫秒的回收。知道程序运行使用 754毫秒,这意味着垃圾回收占用了整个运行时间的大约25%。和其他并发版本相比提升了9%。
此版本的并发算法似乎可以通过更多文件和内核来更好地扩展。 在我看来,复杂性成本是值得的。 可以通过将列表切成每个Goroutine的工作桶来替换该通道。 这无疑会增加更多的复杂性,尽管它可以减少通道引起的某些延迟成本。 对于更多的文件和内核,这可能很重要,但是需要衡量复杂性成本。 您可以尝试一下。
结论
我喜欢比较算法的三个版本的原因是GC如何处理每种情况。在任何版本中,处理文件所需的总内存量不会改变。改变的是程序的分配方式。
当只有一个协程,基本的4M堆内存是所需要的所有内存。当程序一次在运行时放弃所有工作时,GC采取了让堆增长的方法,减少了收集的数量,但运行了更长收集。 当程序在任何给定时间控制正在处理的文件数时,GC就会采用使堆再次保持较小的方法,从而增加了收集数,但运行了较小的收集。 GC采取的每种方法本质上都使程序可以在GC对程序产生最小影响的情况下运行。
| Algorithm | Program | GC Time | % Of GC | # of GC’s | Avg GC | Max Heap |
|------------|---------|----------|---------|-----------|----------|----------|
| freq | 2626 ms | 64.5 ms | ~2% | 232 | 278 μs | 4 meg |
| concurrent | 951 ms | 284.4 ms | ~34% | 23 | 12.3 ms | 200 meg |
| numCPU | 754 ms | 177.7 ms | ~25% | 467 | 380.5 μs | 4 meg |
freqNumCPU 版本还有其他用途,例如更好地处理缓存一致性,这很有帮助。但是,每个程序的GC时间问题差异非常接近,分别为大约284.4ms和177.7ms。在我的计算机上运行该程序的某些天,这些数字甚至更接近。 使用1.13.beta1版进行一些实验,我已经看到两种算法都在相同的时间运行。 可能暗示它们可能是即将来临的一些改进,这些改进使GC可以更好地预测运行方式。
所有这些使我有信心在运行时投入大量工作。 这是一个使用50k goroutine的Web服务,它本质上是一种类似于第一个并发算法的扇出模式。 GC将研究工作量,并找到使服务摆脱困境的最佳步伐。 至少对我来说,不必考虑任何这些都值得入场的代价。